Research Breakthroughs
38 milestones in AI history
Theoretical Foundations (1943–1955)
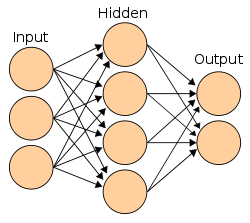
First Mathematical Model of Neural Networks
McCulloch and Pitts published 'A Logical Calculus of Ideas Immanent in Nervous Activity,' creating the first mathematical model of an artificial neuron. They showed that simple binary neurons connected in networks could, in principle, compute any function computable by a Turing machine.

Turing's 'Computing Machinery and Intelligence'
Alan Turing published his landmark paper in the journal Mind, proposing the 'Imitation Game' (now known as the Turing Test) as a way to evaluate machine intelligence. He asked: 'Can machines think?' and argued the question itself was meaningless — what mattered was whether a machine could convincingly imitate human conversation.
Samuel's Checkers Program
Arthur Samuel created a checkers-playing program at IBM that could learn from experience, improving its play over time. He coined the term 'machine learning' to describe programs that learn without being explicitly programmed.
Logic Theorist: The First AI Program
Newell and Simon created the Logic Theorist, often called the first AI program. It could prove mathematical theorems from Whitehead and Russell's Principia Mathematica — and even found a more elegant proof than the original for one theorem. It was debuted at the Dartmouth Conference.
The Birth of AI (1956–1969)

The Dartmouth Conference
A two-month workshop at Dartmouth College where the term 'Artificial Intelligence' was officially coined. The proposal stated: 'Every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it.' This gathering brought together the founders of the field.

The Perceptron
Frank Rosenblatt built the Mark I Perceptron, the first hardware implementation of an artificial neural network. It could learn to classify simple visual patterns. The New York Times reported it as an 'Electronic Brain' that the Navy expected would 'be able to walk, talk, see, write, reproduce itself and be conscious of its existence.'
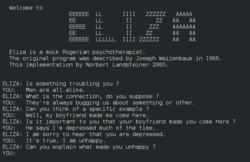
ELIZA: The First Chatbot
Joseph Weizenbaum created ELIZA, a program that simulated a Rogerian psychotherapist using simple pattern matching. Despite being purely rule-based with no understanding, users became emotionally attached to it and insisted it truly understood them — a phenomenon Weizenbaum found deeply disturbing.
SHRDLU: Natural Language Understanding
Terry Winograd created SHRDLU, a program that could understand and respond to English commands about a simulated 'blocks world.' Users could ask it to move objects, answer questions about their arrangement, and even understand pronouns and context within its limited domain.

Shakey the Robot
Shakey was the first mobile robot that could reason about its actions. It combined computer vision, natural language processing, and planning to navigate rooms, push objects, and solve simple tasks. It used the A* search algorithm and STRIPS planner.
DENDRAL: The First Expert System
DENDRAL automated chemical structure determination from mass spectrometry data. It used heuristic rules from domain experts to solve problems that normally required PhD-level expertise. Its successor Meta-DENDRAL could even generate new rules automatically.
First AI Winter (1970–1979)

Perceptrons: The Book That Killed Neural Networks
Minsky and Papert published 'Perceptrons,' mathematically proving that single-layer perceptrons could not solve the XOR problem or other non-linearly separable tasks. While technically correct, the book was widely interpreted as proving neural networks were fundamentally limited — though multi-layer networks could solve these problems.
Backpropagation Discovered (Initially Ignored)
Paul Werbos described the backpropagation algorithm in his PhD thesis — a method for training multi-layer neural networks by propagating errors backward through the network. However, in the anti-neural-network climate of the 1970s, the work went largely unnoticed.
Expert Systems Boom (1980–1987)

Hopfield Networks: Physics Meets Neural Networks
Physicist John Hopfield showed that a type of recurrent neural network could serve as content-addressable memory, using concepts from statistical physics. The network would converge to stable states that could store and retrieve patterns — connecting neuroscience, physics, and computation.

Backpropagation Rediscovered
Rumelhart, Hinton, and Williams published 'Learning Representations by Back-propagating Errors' in Nature, demonstrating that backpropagation could train multi-layer neural networks effectively. The same year, the PDP (Parallel Distributed Processing) group published their influential two-volume work on connectionism.

NETtalk: Neural Network Learns to Speak
NETtalk was a neural network that learned to pronounce English text aloud, starting from babbling sounds and gradually becoming intelligible — mimicking how a child learns to speak. It captured public imagination and demonstrated backpropagation's potential.
Second AI Winter (1988–1993)

LeNet: Convolutional Neural Networks
Yann LeCun demonstrated that convolutional neural networks (CNNs) could be trained with backpropagation to recognize handwritten digits. The refined LeNet-5 (1998) achieved 99%+ accuracy on MNIST and was deployed by banks to read checks — running in ATMs for years.

TD-Gammon: Reinforcement Learning Plays Backgammon
Gerald Tesauro created TD-Gammon, a neural network that learned to play backgammon at expert level through self-play using temporal difference reinforcement learning. It discovered novel strategies that surprised human experts.
Quiet Emergence (1994–2005)
Support Vector Machines
Vapnik and Cortes published their work on Support Vector Machines (SVMs), a method for finding maximum-margin decision boundaries in high-dimensional spaces with unusually strong theoretical guarantees. SVMs quickly became one of the leading approaches for classification problems across text, vision, and bioinformatics.

Long Short-Term Memory (LSTM)
Hochreiter and Schmidhuber published the LSTM architecture, solving the vanishing gradient problem that plagued recurrent neural networks. LSTMs could learn long-range dependencies in sequential data by maintaining a memory cell with gates that controlled information flow.

Deep Learning Breakthrough (2012–2017)

AlexNet: The ImageNet Moment
AlexNet, a deep convolutional neural network, won the ImageNet competition by a staggering margin — reducing the error rate from 26% to 16%. Trained on two NVIDIA GTX 580 GPUs, it was dramatically deeper and more powerful than previous entries. The AI community was stunned.

Word2Vec: Words as Vectors
Google researchers published Word2Vec, showing that relatively small neural networks could efficiently learn meaningful vector representations of words from large text corpora. The famous example `king - man + woman ≈ queen` made the idea vivid: semantic relationships could be captured geometrically in vector space.
DeepMind's DQN Masters Atari Games
DeepMind demonstrated a deep reinforcement learning agent (Deep Q-Network) that learned to play Atari 2600 games directly from pixel inputs, achieving superhuman performance on many games with no task-specific engineering. Google acquired DeepMind for ~$500 million shortly after.

Generative Adversarial Networks (GANs)
Ian Goodfellow introduced GANs — two neural networks (generator and discriminator) competing against each other, one creating fake data and the other trying to detect it. The concept allegedly came to him during a bar conversation. Yann LeCun called GANs 'the most interesting idea in the last 10 years in ML.'

ResNet: Deeper Than Ever
Microsoft Research introduced ResNet with skip connections (residual connections), enabling the training of networks with 152+ layers — 8x deeper than previous networks. ResNet won ImageNet 2015 with 3.57% error, surpassing human-level performance (5.1%) for the first time.

Attention Is All You Need: The Transformer
Eight researchers at Google published 'Attention Is All You Need,' introducing the Transformer architecture. It replaced recurrence with self-attention mechanisms that could process entire sequences in parallel. The paper's title was deliberately bold — and proved prescient.

AlphaGo Zero: Learning From Scratch
AlphaGo Zero achieved superhuman Go performance with ZERO human knowledge — no training data from human games, no hand-crafted features. It learned entirely through self-play, and within 40 days surpassed all previous versions, including the one that beat Lee Sedol.
The Transformer Era (2018–2021)
BERT: Bidirectional Language Understanding
Google published BERT (Bidirectional Encoder Representations from Transformers), which could understand language context from both directions simultaneously. BERT shattered records on 11 NLP benchmarks. Google integrated it into Search, affecting 10% of all queries.
GPT-1: Generative Pre-training
OpenAI released GPT-1, demonstrating that a Transformer trained on vast amounts of text using unsupervised pre-training could then be fine-tuned for specific NLP tasks. With 117 million parameters, it showed the potential of scaling language models.

GPT-2: 'Too Dangerous to Release'
OpenAI announced GPT-2 (1.5 billion parameters) but initially refused to release the full model, calling it 'too dangerous' due to its ability to generate convincing fake text. The decision was controversial — some praised the caution, others called it a publicity stunt. The full model was eventually released in November 2019.
GPT-3: The 175 Billion Parameter Leap
OpenAI released GPT-3 with 175 billion parameters — 100x larger than GPT-2. Without any fine-tuning, GPT-3 could write essays, code, poetry, translate languages, and answer questions through 'few-shot learning' (learning from just a few examples in the prompt). The API launched in beta, enabling thousands of applications.

AlphaFold 2: Protein Folding Solved
DeepMind's AlphaFold 2 solved the 50-year-old protein structure prediction problem, achieving accuracy comparable to experimental methods at CASP14. It could predict how proteins fold from their amino acid sequences — a problem that had stumped biologists for half a century.

DALL-E: Text to Image Generation
OpenAI unveiled DALL-E, a model that could generate images from text descriptions — 'an armchair in the shape of an avocado' became iconic. Built on GPT-3's architecture adapted for images, it showed that language models could bridge the gap between text and visual creativity.
Generative AI Revolution (2022–2024)
GPT-4: Multimodal Intelligence
OpenAI released GPT-4, a multimodal model that could understand both text and images. It passed the bar exam (90th percentile), scored 1410 on the SAT, and demonstrated remarkably nuanced reasoning. It was a massive leap from GPT-3.5 in accuracy, safety, and capability.
Sora: AI Video Generation
OpenAI previewed Sora, a model that could generate photorealistic videos up to a minute long from text descriptions. The quality stunned the world — realistic physics, complex camera movements, and coherent scenes that looked like professional cinematography.
Gemini 1.5 Pro: Million-Token Context
Google released Gemini 1.5 Pro with a 1 million token context window (later extended to 2M) — able to process entire codebases, books, or hours of video in a single prompt. It could find a needle in a haystack across millions of tokens with near-perfect recall.
OpenAI o1: Reasoning Models
OpenAI released o1, a model trained to 'think before it speaks' using chain-of-thought reasoning at inference time. It could solve complex math, coding, and science problems by spending more compute thinking through multi-step solutions — trading speed for accuracy on hard problems.

Nobel Prizes Awarded for AI Work
The 2024 Nobel Prize in Physics went to Geoffrey Hinton and John Hopfield for foundational work on neural networks and machine learning. The Nobel Prize in Chemistry went to Demis Hassabis and John Jumper (AlphaFold) alongside David Baker for computational protein design. AI research received the highest scientific recognition.